本文最后更新于 2023-12-31 ,文中内容可能已过时。
指一组相关数据的有序集合,通常存储在外部介质(如磁盘)上,使用时才调入内存。
在操作系统中把每一个与主机相连的输入、输出设备看作是一个文件,把它们的输入、输出等同于对磁盘文件的读和写。
计算机的存储在物理上是二进制的,所以物理上所有的磁盘文件本质上都是一样的:以字节为单位进行顺序存储。
从用户或者操作系统使用的角度(逻辑上)把文件分为:
文本文件:基于字符编码的文件
二进制文件:基于值编码的文件
基于字符编码,常见编码有ASCII、UNICODE等
一般可以使用文本编辑器直接打开
数5678的以ASCII存储形式(ASCII码)为:00110101 00110110 00110111 00111000
基于值编码,自己根据具体应用,指定某个值是什么意思
把内存中的数据按其在内存中的存储形式原样输出到磁盘上
数5678的存储形式(二进制码)为:00010110 00101110
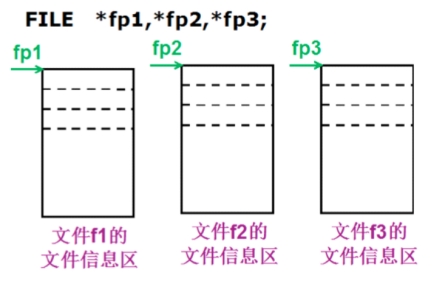
在C语言中用一个指针变量指向一个文件,这个指针称为文件指针。
1
2
3
4
5
6
7
8
9
10
11
12
typedef struct
{
short level ; //缓冲区"满"或者"空"的程度
unsigned flags ; //文件状态标志
char fd ; //文件描述符
unsigned char hold ; //如无缓冲区不读取字符
short bsize ; //缓冲区的大小
unsigned char * buffer ; //数据缓冲区的位置
unsigned ar ; //指针,当前的指向
unsigned istemp ; //临时文件,指示器
short token ; //用于有效性的检查
} FILE ;
FILE是系统使用typedef定义出来的有关文件信息的一种结构体类型,结构中含有文件名、文件状态和文件当前位置等信息。
声明FILE结构体类型的信息包含在头文件“stdio.h”中,一般设置一个指向FILE类型变量的指针变量,然后通过它来引用这些FILE类型变量。通过文件指针就可对它所指的文件进行各种操作。
C语言中有三个特殊的文件指针由系统默认打开,用户无需定义即可直接使用:
stdin: 标准输入,默认为当前终端(键盘),我们使用的scanf、getchar函数默认从此终端获得数据。stdout:标准输出,默认为当前终端(屏幕),我们使用的printf、puts函数默认输出信息到此终端。stderr:标准出错,默认为当前终端(屏幕),我们使用的perror函数默认输出信息到此终端。
任何文件使用之前必须打开:
1
2
3
4
5
6
7
8
9
#include <stdio.h>
FILE * fopen ( const char * filename , const char * mode );
功能:打开文件
参数:
filename :需要打开的文件名,根据需要加上路径
mode :打开文件的模式设置
返回值:
成功:文件指针
失败: NULL
第一个参数的几种形式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
FILE * fp_passwd = NULL ;
//相对路径:
//打开当前目录passdw文件:源文件(源程序)所在目录
FILE * fp_passwd = fopen ( "passwd.txt" , "r" );
//打开当前目录(test)下passwd.txt文件
fp_passwd = fopen ( ". / test / passwd.txt" , "r" );
//打开当前目录上一级目录(相对当前目录)passwd.txt文件
fp_passwd = fopen ( ".. / passwd.txt" , "r" );
//绝对路径:
//打开C盘test目录下一个叫passwd.txt文件
fp_passwd = fopen ( "c:/test/passwd.txt" , "r" );
第二个参数的几种形式(打开文件的方式):
打开模式 含义
r或rb以只读方式打开一个文本文件(不创建文件,若文件不存在则报错)
w或wb以写方式打开文件(如果文件存在则清空文件,文件不存在则创建一个文件)
a或ab以追加方式打开文件,在末尾添加内容,若文件不存在则创建文件
r+或rb+以可读、可写的方式打开文件(不创建新文件)
w+或wb+以可读、可写的方式打开文件(如果文件存在则清空文件,文件不存在则创建一个文件)
a+或ab+以添加方式打开可读、可写的文件。若文件不存在则创建文件;如果文件存在,则写入的数据会被加到文件尾后,即文件原先的内容会被保留。
注意:
b是二进制模式的意思,b只是在Windows有效,在Linux用r和rb的结果是一样的Unix和Linux下所有的文本文件行都是\n结尾,而Windows所有的文本文件行都是\r\n结尾在Windows平台下,以“文本”方式打开文件,不加b:
当读取文件的时候,系统会将所有的 “\r\n” 转换成 “\n”
当写入文件的时候,系统会将 “\n” 转换成 “\r\n” 写入
以"二进制"方式打开文件,则读写都不会进行这样的转换
在Unix/Linux平台下,“文本”与“二进制”模式没有区别,"\r\n" 作为两个字符原样输入输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
int main ( void )
{
FILE * fp = NULL ;
// "\\"这样的路径形式,只能在windows使用
// "/"这样的路径形式,windows和linux平台下都可用,建议使用这种
// 路径可以是相对路径,也可是绝对路径
fp = fopen ( "../test" , "w" );
//fp = fopen("..\\test", "w");
if ( fp == NULL ) //返回空,说明打开失败
{
//perror()是标准出错打印函数,能打印调用库函数出错原因
perror ( "open" );
return - 1 ;
}
return 0 ;
}
任何文件在使用后应该关闭:
打开的文件会占用内存资源,如果总是打开不关闭,会消耗很多内存
一个进程同时打开的文件数是有限制的,超过最大同时打开文件数,再次调用fopen打开文件会失败
如果没有明确的调用fclose关闭打开的文件,那么程序在退出的时候,操作系统会统一关闭。
1
2
3
4
5
6
7
8
9
10
11
12
#include <stdio.h>
int fclose ( FILE * stream );
功能:关闭先前 fopen () 打开的文件。此动作让缓冲区的数据写入文件中,并释放系统所提供的文件资源。
参数:
stream :文件指针
返回值:
成功: 0
失败: - 1
FILE * fp = NULL ;
fp = fopen ( "abc.txt" , "r" );
fclose ( fp );
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <stdio.h>
int fputc ( int ch , FILE * stream );
功能:将 ch转换为unsigned char后写入stream指定的文件中
参数:
ch :需要写入文件的字符
stream :文件指针
返回值:
成功:成功写入文件的字符
失败:返回 - 1
char buf [] = "this is a test for fputc" ;
int i = 0 ;
int n = strlen ( buf );
for ( i = 0 ; i < n ; i ++ )
{
//往文件fp写入字符buf[i]
int ch = fputc ( buf [ i ], fp );
printf ( "ch = %c \n " , ch );
}
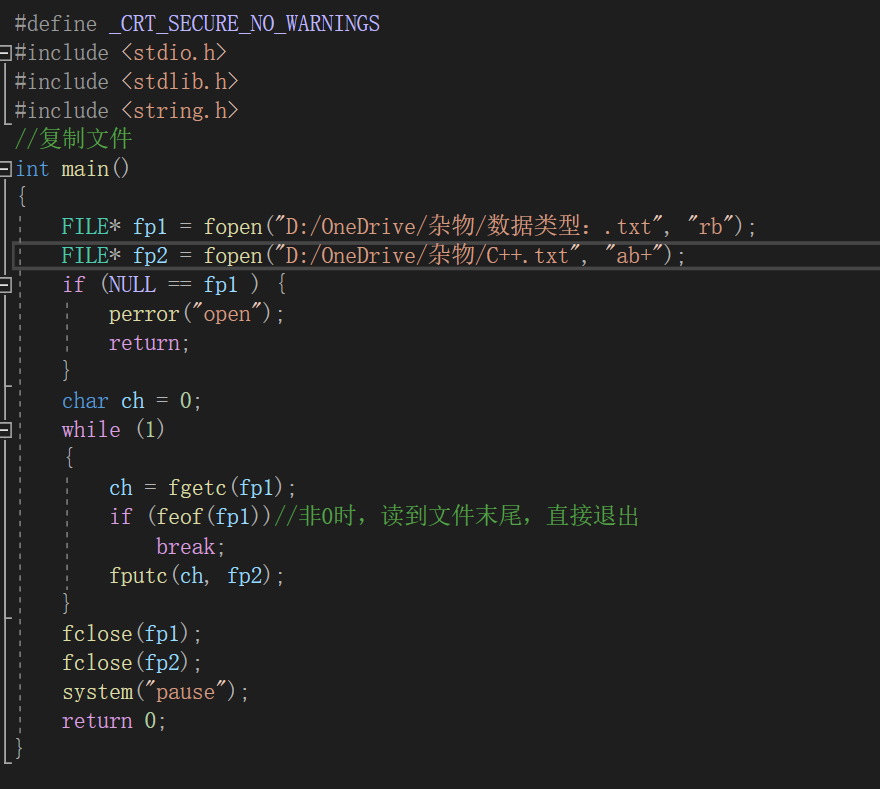
在C语言中,EOF表示文件结束符(end of file)。在while循环中以EOF作为文件结束标志,这种以EOF作为文件结束标志的文件,必须是文本文件。在文本文件中,数据都是以字符的ASCII代码值的形式存放。我们知道,ASCII代码值的范围是0~127,不可能出现-1,因此可以用EOF作为文件结束标志。
当把数据以二进制形式存放到文件中时,就会有-1值的出现,因此不能采用EOF作为二进制文件的结束标志。为解决这一个问题,ANSI C提供一个feof函数,用来判断文件是否结束。feof函数既可用以判断二进制文件又可用以判断文本文件。
1
2
3
4
5
6
7
8
#include <stdio.h>
int feof ( FILE * stream );
功能:检测是否读取到了文件结尾。判断的是最后一次“读操作的内容”,不是当前位置内容 ( 上一个内容 ) 。
参数:
stream :文件指针
返回值:
非 0 值:已经到文件结尾
0 :没有到文件结尾
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
#include <stdio.h>
int fgetc ( FILE * stream );
功能:从 stream指定的文件中读取一个字符
参数:
stream :文件指针
返回值:
成功:返回读取到的字符
失败: - 1
char ch ;
#if 0
while ((ch = fgetc(fp)) != EOF)
{
printf("%c", ch);
}
printf("\n");
#endif
while ( ! feof ( fp )) //文件没有结束,则执行循环
{
ch = fgetc ( fp );
printf ( "%c" , ch );
}
printf ( " \n " );
1
2
3
4
5
6
7
8
9
#include <stdio.h>
int fputs ( const char * str , FILE * stream );
功能:将 str所指定的字符串写入到stream指定的文件中 ,字符串结束符 '\0' 不写入文件。
参数:
str :字符串
stream :文件指针
返回值:
成功: 0
失败: - 1
1
2
3
4
5
6
7
8
char * buf [] = { "123456 \n " , "bbbbbbbbbb \n " , "ccccccccccc \n " };
int i = 0 ;
int n = 3 ;
for ( i = 0 ; i < n ; i ++ )
{
int len = fputs ( buf [ i ], fp );
printf ( "len = %d \n " , len );
}
1
2
3
4
5
6
7
8
9
10
#include <stdio.h>
char * fgets ( char * str , int size , FILE * stream );
功能:从 stream指定的文件内读入字符 ,保存到 str所指定的内存空间 ,直到出现换行字符、读到文件结尾或是已读了 size - 1 个字符为止,最后会自动加上字符 '\0' 作为字符串结束。
参数:
str :字符串
size :指定最大读取字符串的长度( size - 1 )
stream :文件指针
返回值:
成功:成功读取的字符串
读到文件尾或出错: NULL
1
2
3
4
5
6
7
8
9
10
11
char buf [ 100 ] = 0 ;
while ( ! feof ( fp )) //文件没有结束
{
memset ( buf , 0 , sizeof ( buf ));
char * p = fgets ( buf , sizeof ( buf ), fp );
if ( p != NULL )
{
printf ( "buf = %s" , buf );
}
}
1
2
3
4
5
6
7
8
9
#include <stdio.h>
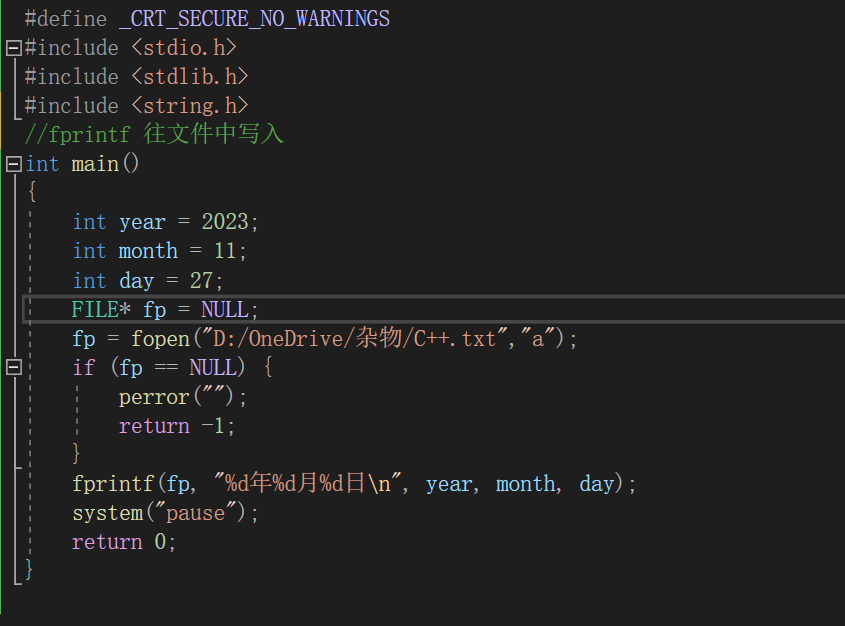
int fprintf ( FILE * stream , const char * format , ...);
功能:根据参数 format字符串来转换并格式化数据 ,然后将结果输出到 stream指定的文件中 ,指定出现字符串结束符 '\0' 为止。
参数:
stream :已经打开的文件
format :字符串格式,用法和 printf () 一样
返回值:
成功:实际写入文件的字符个数
失败: - 1
1
fprintf ( fp , "%d %d %d \n " , 1 , 2 , 3 );
1
2
3
4
5
6
7
8
9
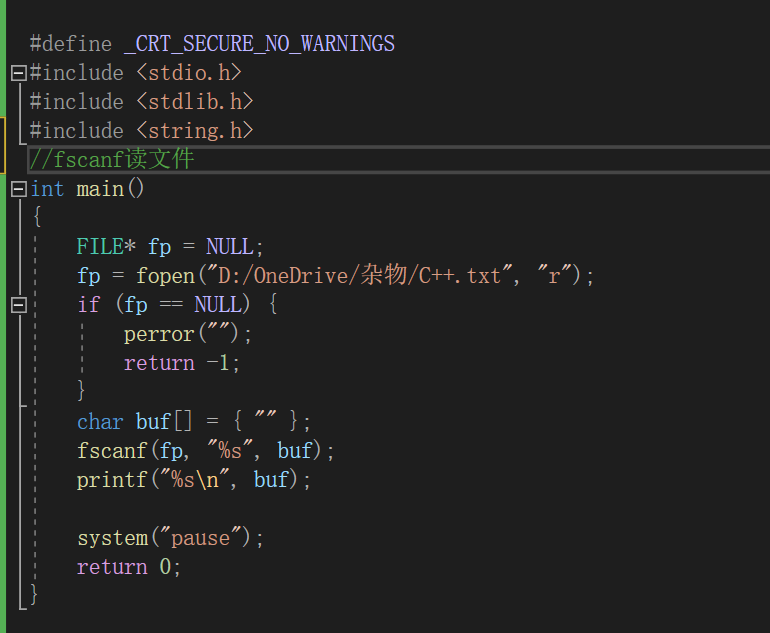
#include <stdio.h>
int fscanf ( FILE * stream , const char * format , ...);
功能:从 stream指定的文件读取字符串 ,并根据参数 format字符串来转换并格式化数据 。
参数:
stream :已经打开的文件
format :字符串格式,用法和 scanf () 一样
返回值:
成功:参数数目,成功转换的值的个数
失败: - 1
1
2
3
4
5
int a = 0 ;
int b = 0 ;
int c = 0 ;
fscanf ( fp , "%d %d %d \n " , & a , & b , & c );
printf ( "a = %d, b = %d, c = %d \n " , a , b , c );
1
2
3
4
5
6
7
8
9
10
11
#include <stdio.h>
size_t fwrite ( const void * ptr , size_t size , size_t nmemb , FILE * stream );
功能:以数据块的方式给文件写入内容
参数:
ptr :准备写入文件数据的地址
size : size_t 为 unsigned int类型 ,此参数指定写入文件内容的块数据大小
nmemb :写入文件的块数,写入文件数据总大小为: size * nmemb
stream :已经打开的文件指针
返回值:
成功:实际成功写入文件数据的块数目,此值和 nmemb 相等
失败: 0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
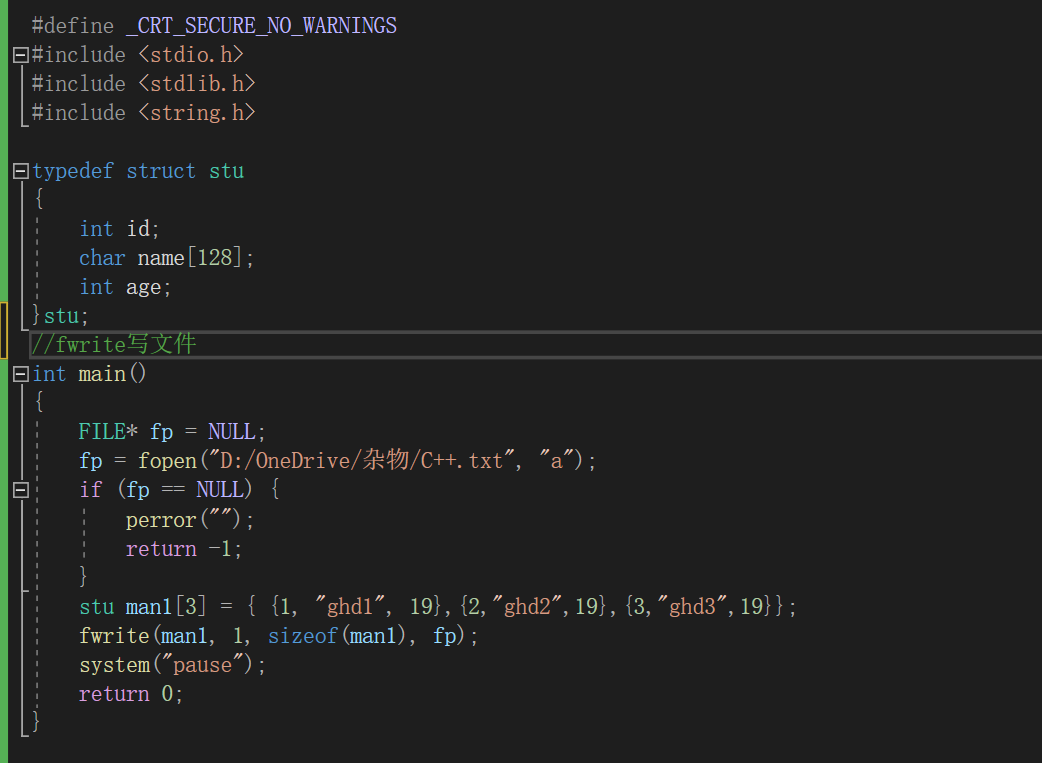
typedef struct Stu
{
char name [ 50 ];
int id ;
} Stu ;
Stu s [ 3 ];
int i = 0 ;
for ( i = 0 ; i < 3 ; i ++ )
{
sprintf ( s [ i ]. name , "stu%d%d%d" , i , i , i );
s [ i ]. id = i + 1 ;
}
int ret = fwrite ( s , sizeof ( Stu ), 3 , fp );
printf ( "ret = %d \n " , ret );
1
2
3
4
5
6
7
8
9
10
11
#include <stdio.h>
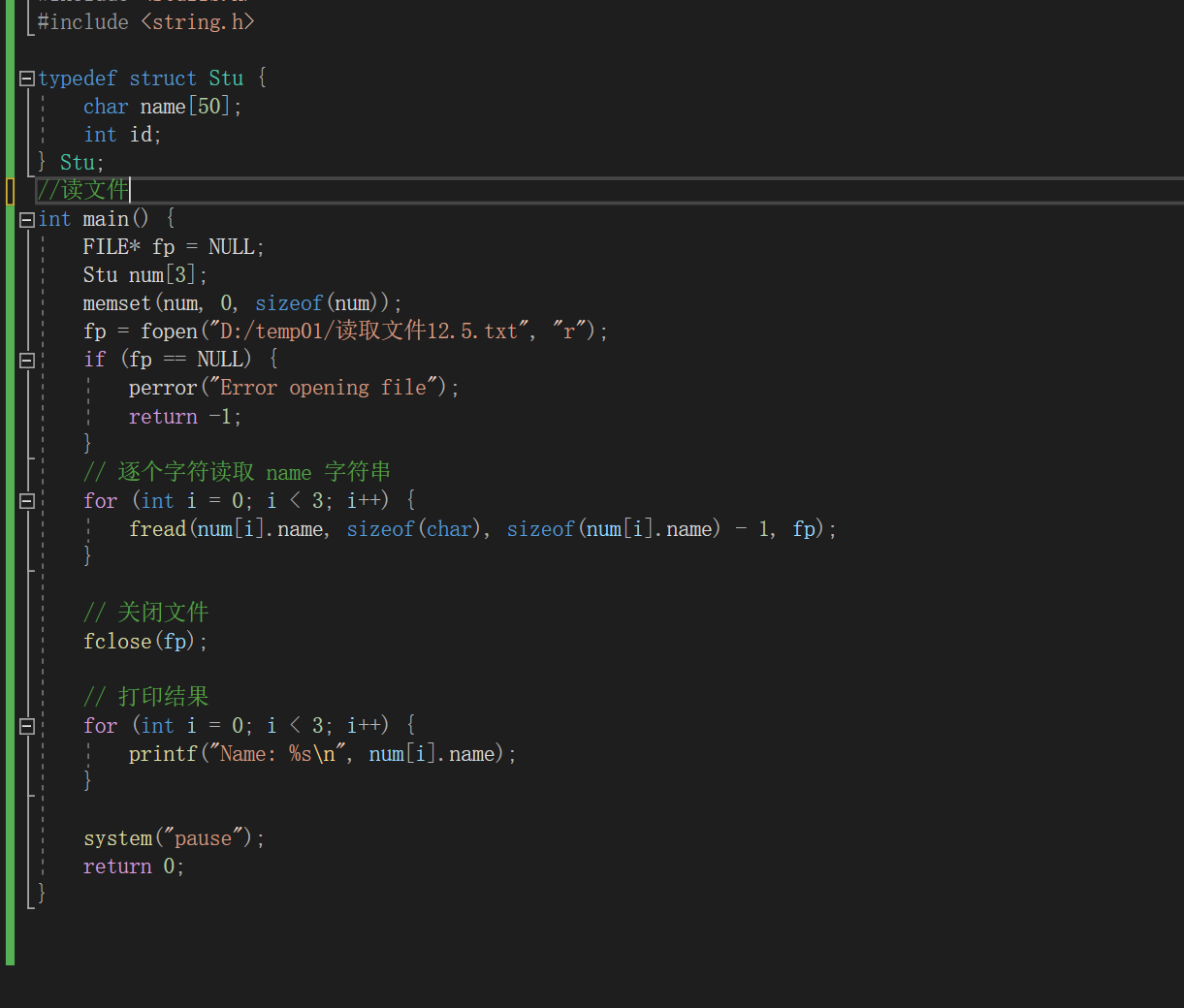
size_t fread ( void * ptr , size_t size , size_t nmemb , FILE * stream );
功能:以数据块的方式从文件中读取内容
参数:
ptr :存放读取出来数据的内存空间
size : size_t 为 unsigned int类型 ,此参数指定读取文件内容的块数据大小
nmemb :读取文件的块数,读取文件数据总大小为: size * nmemb
stream :已经打开的文件指针
返回值:
成功:实际成功读取到内容的块数,如果此值比 nmemb小 ,但大于 0 ,说明读到文件的结尾。
失败: 0
fread 是 C 语言标准库中的一个函数,用于从文件中读取二进制数据。它的原型如下:
1
2
cCopy code
size_t fread(void *ptr, size_t size, size_t count, FILE *stream);
这个函数的作用是从指定的文件流 stream 中读取数据,将读取的数据存储到 ptr 指向的内存块中。它的参数含义如下:
ptr:指向存储读取数据的内存块的指针。size:每个数据项的字节数。count:要读取的数据项的数量。stream:文件流指针,指定要读取数据的文件。
fread 函数返回实际读取的数据项的数量,如果发生错误或文件结束,返回值可能小于 count。
下面是一些关于 fread 函数的详细说明:
数据读取 :fread 从文件中读取数据,并存储到 ptr 指向的内存块中。它按照每个数据项的字节数和数量来读取数据。文件指针位置 :每次调用 fread 后,文件指针会向前移动,移动的字节数等于读取的字节数。这意味着多次调用 fread 会逐渐将文件指针移动到文件的末尾。返回值 :fread 返回实际读取的数据项的数量。如果返回值小于 count,可能是因为读取到文件末尾或发生了错误。结构体读取 :可以使用 fread 一次性读取整个结构体的内容。这对于从文件中读取二进制数据结构非常有用。
下面是一个简单的示例,演示如何使用 fread 从文件中读取整数数组:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
cCopy code # include < stdio . h >
int main () {
FILE * fp = fopen ( "data.bin" , "rb" );
if ( fp == NULL ) {
perror ( "Error opening file" );
return 1 ;
}
int data [ 5 ];
size_t elements_read = fread ( data , sizeof ( int ), 5 , fp );
fclose ( fp );
printf ( "Read %zu elements: " , elements_read );
for ( size_t i = 0 ; i < elements_read ; i ++ ) {
printf ( "%d " , data [ i ]);
}
return 0 ;
}
在这个例子中,我们打开一个二进制文件(使用 "rb" 模式),并尝试读取一个包含 5 个整数的数组。fread 函数会读取整个数组的内容,然后我们打印实际读取的元素数量和数组的内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
typedef struct Stu
{
char name [ 50 ];
int id ;
} Stu ;
Stu s [ 3 ];
int ret = fread ( s , sizeof ( Stu ), 3 , fp );
printf ( "ret = %d \n " , ret );
int i = 0 ;
for ( i = 0 ; i < 3 ; i ++ )
{
printf ( "s = %s, %d \n " , s [ i ]. name , s [ i ]. id );
}
fseek 是 C 语言标准库中的一个函数,用于在文件流中移动文件指针的位置。这个函数允许你在文件中的任意位置进行读写操作。它的原型如下:
1
2
cCopy code
int fseek(FILE *stream, long offset, int whence);
这个函数的参数含义如下:
fseek 返回零表示成功,非零表示失败。失败可能是因为文件指针越界或发生了其他错误。
下面是一些关于 fseek 函数的详细说明:
文件指针位置 :fseek 允许你在文件中移动文件指针的位置。通过设置 offset 和 whence 参数,你可以将文件指针移动到文件的任何位置。文件末尾定位 :如果你想将文件指针移动到文件的末尾,可以使用 fseek(fp, 0, SEEK_END);。这是一个常见的用法,特别是当你需要获取文件大小时。文件指针越界 :在使用 fseek 时,要注意不要将文件指针移动到文件末尾之后。这可能导致未定义的行为。
下面是一个简单的示例,演示如何使用 fseek 在文件中定位并读取数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
cCopy code # include < stdio . h >
int main () {
FILE * fp = fopen ( "data.txt" , "r" );
if ( fp == NULL ) {
perror ( "Error opening file" );
return 1 ;
}
// 将文件指针移动到文件的第 10 个字节处
if ( fseek ( fp , 10 , SEEK_SET ) != 0 ) {
perror ( "Error seeking in file" );
fclose ( fp );
return 1 ;
}
// 读取并打印文件中的剩余内容
int ch ;
while (( ch = fgetc ( fp )) != EOF ) {
putchar ( ch );
}
fclose ( fp );
return 0 ;
}
我们打开一个文本文件,将文件指针移动到文件的第 10 个字节处,然后读取并打印文件中的剩余内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
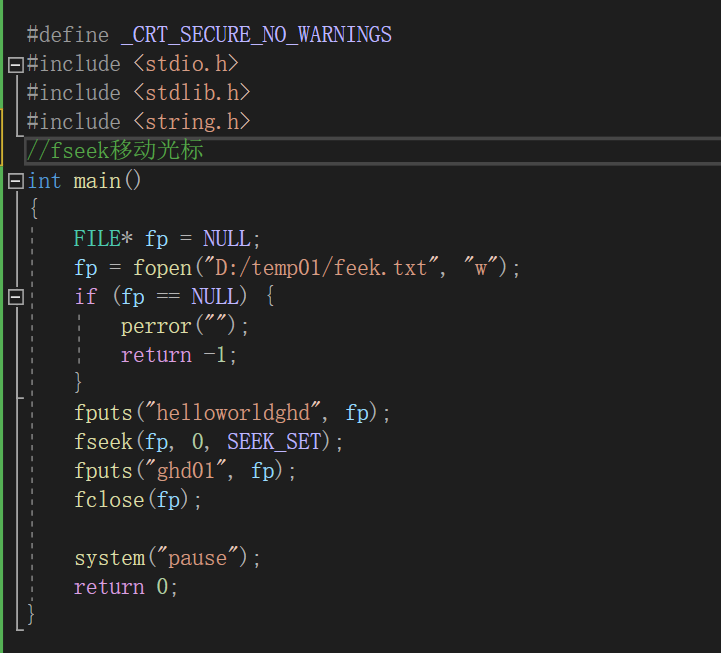
#include <stdio.h>
int fseek ( FILE * stream , long offset , int whence );
功能:移动文件流(文件光标)的读写位置。
参数:
stream :已经打开的文件指针
offset :根据 whence来移动的位移数 (偏移量),可以是正数,也可以负数,如果正数,则相对于 whence往右移动 ,如果是负数,则相对于 whence往左移动 。如果向前移动的字节数超过了文件开头则出错返回,如果向后移动的字节数超过了文件末尾,再次写入时将增大文件尺寸。
whence :其取值如下:
SEEK_SET :从文件开头移动 offset个字节
SEEK_CUR :从当前位置移动 offset个字节
SEEK_END :从文件末尾移动 offset个字节
返回值:
成功: 0
失败: - 1
#include <stdio.h>
long ftell ( FILE * stream );
功能:获取文件流(文件光标)的读写位置。
参数:
stream :已经打开的文件指针
返回值:
成功:当前文件流(文件光标)的读写位置
失败: - 1
#include <stdio.h>
void rewind ( FILE * stream );
功能:把文件流(文件光标)的读写位置移动到文件开头。
参数:
stream :已经打开的文件指针
返回值:
无返回值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
typedef struct Stu
{
char name [ 50 ];
int id ;
} Stu ;
//假如已经往文件写入3个结构体
//fwrite(s, sizeof(Stu), 3, fp);
Stu s [ 3 ];
Stu tmp ;
int ret = 0 ;
//文件光标读写位置从开头往右移动2个结构体的位置
fseek ( fp , 2 * sizeof ( Stu ), SEEK_SET );
//读第3个结构体
ret = fread ( & tmp , sizeof ( Stu ), 1 , fp );
if ( ret == 1 )
{
printf ( "[tmp]%s, %d \n " , tmp . name , tmp . id );
}
//把文件光标移动到文件开头
//fseek(fp, 0, SEEK_SET);
rewind ( fp );
ret = fread ( s , sizeof ( Stu ), 3 , fp );
printf ( "ret = %d \n " , ret );
int i = 0 ;
for ( i = 0 ; i < 3 ; i ++ )
{
printf ( "s === %s, %d \n " , s [ i ]. name , s [ i ]. id );
}
ftell 是 C 语言标准库中的一个函数,用于获取文件指针的当前位置。这个函数返回当前文件指针相对于文件起始位置的字节数。
ftell 函数的原型如下:
1
2
cCopy code
long ftell ( FILE * stream );
这个函数的参数是一个文件流指针 stream,指定要获取位置的文件。返回值是 long 类型,表示文件指针的当前位置。如果发生错误,ftell 返回 -1L。
以下是一些关于 ftell 函数的详细说明:
文件指针位置 :ftell 用于获取文件指针的当前位置,返回值表示文件指针相对于文件起始位置的字节数。long 类型long,因为文件的大小可能大于 int 能够表示的范围。fseek 和 ftell 的组合fseek 和 ftell 一起使用,用于定位和获取文件指针的位置。fseek 用于移动文件指针,而 ftell 用于获取当前位置。
下面是一个简单的示例,演示如何使用 ftell 函数获取文件指针的当前位置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
cCopy code # include < stdio . h >
int main () {
FILE * fp = fopen ( "data.txt" , "r" );
if ( fp == NULL ) {
perror ( "Error opening file" );
return 1 ;
}
// 使用 ftell 获取当前文件指针位置
long position = ftell ( fp );
if ( position == - 1L ) {
perror ( "Error getting file position" );
fclose ( fp );
return 1 ;
}
printf ( "Current file position: %ld \n " , position );
fclose ( fp );
return 0 ;
}
在这个例子中,我们打开一个文本文件,使用 ftell 获取文件指针的当前位置,然后打印该位置。请注意,ftell 返回的值在文件指针移动后仍然有效。
stat 函数是 C 语言标准库中提供的一个用于获取文件或文件系统信息的函数。它可以获取指定文件的状态信息,并将这些信息存储在一个结构体中。在 POSIX 标准中,stat 函数的原型为:
1
2
cCopy code
int stat ( const char * path , struct stat * buf );
其中,path 是文件路径的字符串,buf 是一个指向 struct stat 结构体的指针,用于存储文件状态信息。stat 函数的返回值为 0 表示成功,-1 表示失败。
以下是关于 stat 函数的详细说明:
结构体 struct stat :
struct stat 结构体包含了文件的多种属性,例如文件大小、最后修改时间、权限等。结构体定义在头文件 sys/stat.h 中。
文件路径 path :
path 参数是一个表示文件路径的字符串。该字符串可以是相对路径或绝对路径。
成功与失败 :
如果函数调用成功,返回值为 0。
如果函数调用失败,返回值为 -1,并设置全局变量 errno 表示错误的类型。
文件状态信息 :
struct stat 结构体中的成员用于存储文件的各种信息,0例如文件大小、权限、最后访问时间等。常用的结构体成员包括:
st_size:文件大小(字节数)。st_mode:文件类型和权限。st_atime:最后访问时间。st_mtime:最后修改时间。st_ctime:最后状态改变时间。
文件类型和权限 :
文件类型和权限信息存储在 st_mode 成员中。
通过宏定义进行解析,例如 S_ISREG(mode) 判断是否是普通文件,S_ISDIR(mode) 判断是否是目录等。
下面是一个简单的示例,演示如何使用 stat 函数获取文件信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
cCopy code # include < stdio . h >
#include <sys/stat.h>
int main () {
const char * filename = "example.txt" ;
struct stat file_info ;
if ( stat ( filename , & file_info ) == 0 ) {
printf ( "File size: %ld bytes \n " , file_info . st_size );
printf ( "File permissions: %o \n " , file_info . st_mode & 0777 );
printf ( "Last access time: %ld \n " , file_info . st_atime );
} else {
perror ( "Error getting file information" );
}
return 0 ;
}
在这个例子中,我们使用 stat 函数获取了一个文件的大小、权限和最后访问时间,并打印了这些信息。请注意,为了更好地理解文件权限,我们使用了 & 0777 来提取权限的部分。
remove 和 rename 是 C 语言标准库中用于文件操作的两个函数。
remove 函数用于删除指定的文件。其原型如下:
1
2
cCopy code
int remove ( const char * filename );
filename 参数是一个字符串,表示要删除的文件的路径。返回值为 0 表示删除成功,-1 表示删除失败。在删除失败时,全局变量 errno 会被设置以指示具体的错误原因。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
cCopy code # include < stdio . h >
int main () {
const char * filename = "example.txt" ;
if ( remove ( filename ) == 0 ) {
printf ( "File '%s' deleted successfully. \n " , filename );
} else {
perror ( "Error deleting file" );
}
return 0 ;
}
rename 函数用于更改文件的名称或移动文件。其原型如下:
1
2
cCopy code
int rename ( const char * old_filename , const char * new_filename );
old_filename 参数是一个字符串,表示要更改的文件的路径。new_filename 参数是一个字符串,表示文件的新路径或新名称。返回值为 0 表示更名成功,-1 表示更名失败。在失败时,errno 会被设置以指示错误原因。
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
cCopy code # include < stdio . h >
int main () {
const char * old_filename = "old.txt" ;
const char * new_filename = "new.txt" ;
if ( rename ( old_filename , new_filename ) == 0 ) {
printf ( "File '%s' renamed to '%s' successfully. \n " , old_filename , new_filename );
} else {
perror ( "Error renaming file" );
}
return 0 ;
}
这两个函数在文件操作中很有用,remove 可用于删除文件,而 rename 可用于更改文件的名称或将文件移动到不同的位置。请注意,rename 函数也可以用于移动文件,通过将文件的新路径作为目标路径传递给 rename。
文件缓冲区是指对文件读写操作进行缓冲管理的一块内存区域。在 C 语言中,标准库提供了一套 I/O 缓冲机制,主要通过 FILE 结构体中的缓冲区来实现。
全缓冲(Fully Buffered) :
当文件大小超过一定阈值时,标准 I/O 库采用全缓冲,即在内存中为文件分配一个大的缓冲区,多次读写操作都在这个缓冲区中进行,减少了系统调用的次数,提高了性能。
FILE 结构体中的缓冲区通过 setvbuf 函数进行设置。
行缓冲(Line Buffered) :
当文件是一个终端设备(例如终端或控制台)时,标准 I/O 库采用行缓冲,即每次读写操作都以换行符为界进行缓冲,或者当缓冲区满时进行缓冲。
对于标准输入和标准输出,默认是行缓冲,但可以通过 setvbuf 函数进行更改。
无缓冲(Unbuffered) :
当文件是一个字符设备(例如终端)且是单字符 I/O 操作时,标准 I/O 库采用无缓冲。
无缓冲模式下,每个字符都立即进行 I/O 操作。
文件关闭时刷新缓冲 :
在关闭文件之前,标准 I/O 库会尝试刷新缓冲区,将缓冲区中的内容写入文件。
强制刷新缓冲 :
缓冲区溢出 :
当进行写操作时,如果缓冲区满了,或者调用 fflush,或者文件关闭时,都会导致缓冲区被刷新。如果数据量过大,可能导致缓冲区溢出。
定向 I/O 函数 :
fseek, ftell, rewind 等定向 I/O 函数可能会影响缓冲区的状态。例如,使用 fseek 定位到文件中某个位置时,fflush 可能会被调用。
线程安全性 :
默认情况下,标准 I/O 操作是不线程安全的。在多线程环境中,要注意使用 flockfile 和 funlockfile 来保护对同一文件流的并发访问。
强制关闭文件流 :
使用 fclose 关闭文件时,系统会尝试刷新缓冲区。如果强制关闭程序(例如使用 exit 函数),则可能导致缓冲区未刷新。
总体而言,理解文件缓冲的工作机制并注意缓冲区的刷新是确保文件操作正确和高效的关键。根据应用的特定需求,可以通过 setvbuf 函数来调整文件缓冲类型。